

Talk · Cloud Native Gandhinagar
Abstracting the Abyss:
How to Run Production Data
Workloads on Any Kubernetes Cluster
Agenda
What We'll Cover Today
- 01 3 doors for running data — trade-offs & traps
- 02 Kubernetes as the universal data platform
- 03 Running production databases on Kubernetes
- 04 OpenEverest — what it is, and where it's going
Three Paths
3 Doors for Running Data in Your Org
Managed Services
RDS, MongoDB Atlas, Cloud SQL…
- Fast to get started
- Vendor handles operations
- Expensive at scale
- Locked into one cloud
Legacy & DIY
Custom scripts, VMs, bare metal…
- Full control over setup
- Requires a dedicated DBA team
- Manual, error-prone processes
- Hard to scale consistently
Cloud Native
Kubernetes Operators, GitOps…
- Runs on any infrastructure
- Operations as code
- No vendor lock-in
- Day-2 ops automated
Door 1 · Managed Services
The Golden
Cage
Managed databases feel easy — until you start scaling. Then the hidden costs and constraints start to show.
RDS, MongoDB Atlas, Cloud SQL, PlanetScale, Neon…
Vendor Lock-in
Your data, their APIs, their region list, their outage schedule. Migrating out is painful and expensive.
Unpredictable Costs
Bills that grow non-linearly with traffic. Egress fees. Storage markups. Per-connection pricing surprises.
Limited Control
Can't tune storage drivers, OS configs, or networking. You get what they expose — nothing more.
Data Sovereignty
Regulated industries can't always let a third party hold the data. Compliance becomes your problem.
Door 2 · Legacy & DIY
The Hidden Tax of
Doing It Yourself
Full control sounds great — until your database expert leaves and no one knows how the provisioning script works.
Ticket-driven Provisioning
Developers open a ticket. A DBA creates the database. Days pass. Everyone is frustrated.
Zombie Scripts
Bash scripts and Ansible playbooks written years ago. Nobody wants to touch them. They "just work" — until they don't.
Knowledge Silos
One person knows the replication setup. Another knows the backup cron. Nobody knows both.
Doesn't Scale
10 databases: manageable. 100 databases: chaos. The linear growth of effort kills the team.
Incident-driven Ops
No automated failover. Failover is a 2 AM phone call, a runbook, and adrenaline.
Upgrade Paralysis
Upgrading PostgreSQL 13 → 16? That's a project, not a task. So it gets deferred indefinitely.
Door 3 · Cloud Native
Enter Kubernetes —
The Unifier
One API. Any infrastructure. Kubernetes became the platform for building platforms — and it runs everywhere.
The Myth vs. Reality
Kubernetes has grown up.
Data workloads belong.
Kubernetes 1.0 — Stateless first
Deployments and ReplicaSets designed for ephemeral, interchangeable pods. Storage was an afterthought.
StatefulSets & PersistentVolumes
Stable network identities, ordered deployment, and persistent storage. The first real foundation for data.
Storage Classes & CSI Drivers
Dynamic provisioning, volume snapshots, local NVMe support. Cloud-grade storage on any backend.
Operators — domain knowledge as code
PostgreSQL, MySQL, MongoDB, Redis — all managed by operators that encode DBA expertise into the control loop. This is where it gets interesting.
Cloud Native Databases
Kubernetes Operators: The Game Changer
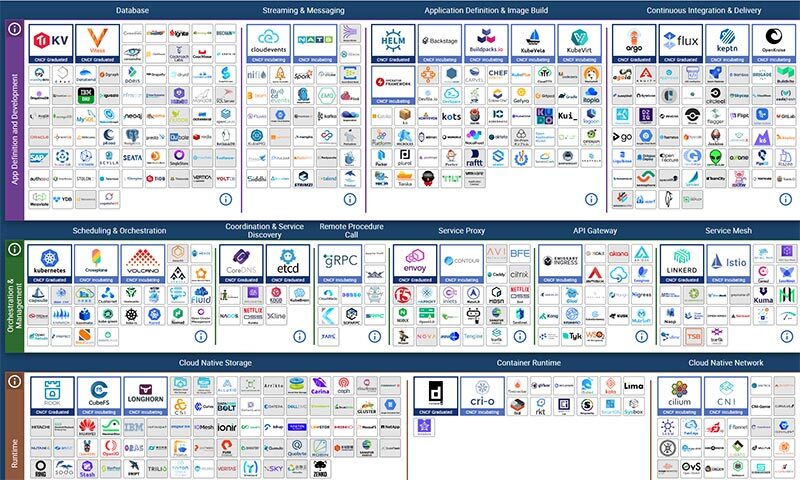
CNCF Ecosystem
Operators Are Just the Entry Point
Running on Kubernetes means your database plugs into an entire ecosystem of battle-tested open source tooling — all cloud native, all composable.
Part III
Production Databases
on Kubernetes
Four pillars that separate a database cluster that survives from one that doesn't.
Production Databases · Pillar 1
Topology & High Availability
Production Databases · Pillar 2
Compute: Guaranteed QoS
Misusing requests and limits is the most common way databases die on Kubernetes — killed by the Linux OOM killer at 3 AM.
Production Databases · Pillar 3
Storage: Three Tiers
Storage is where 80% of Kubernetes database issues live. Navigate it with a clear tiering strategy.
Production Databases · Pillar 4
Backups & Point-in-Time Recovery
The Problem
Operators Are Great. Until You Have More Than One.
Every database engine has its own operator — sometimes several. Each one has its own API, its own CRDs, its own assumptions about how to wire up the rest of your stack.
The operators are mature. The problem is the layer above them — the one that doesn't exist yet.
Introducing
A unified, open source control plane for running production databases on any Kubernetes cluster — any cloud, any engine.
development
across organizations
vendor lock-in, ever
OpenEverest is a CNCF Sandbox project — part of the Cloud Native Computing Foundation ecosystem OpenEverest
One Platform. Any Database. Any Cluster.
OpenEverest abstracts the operator layer — you get one API, one UI, one operational model, regardless of which database or operator runs underneath.
OpenEverest Today
The UI You Actually Ship With
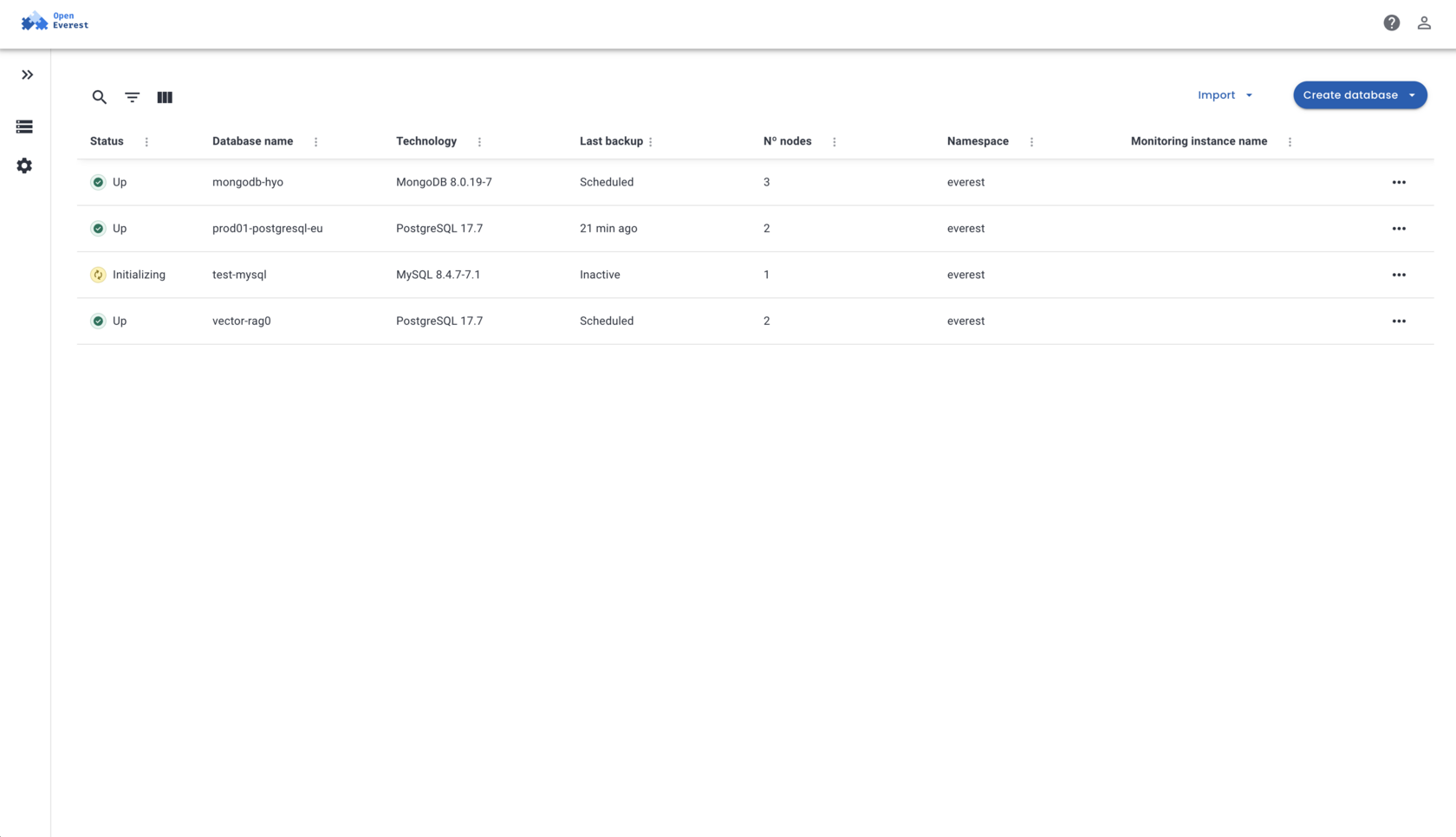
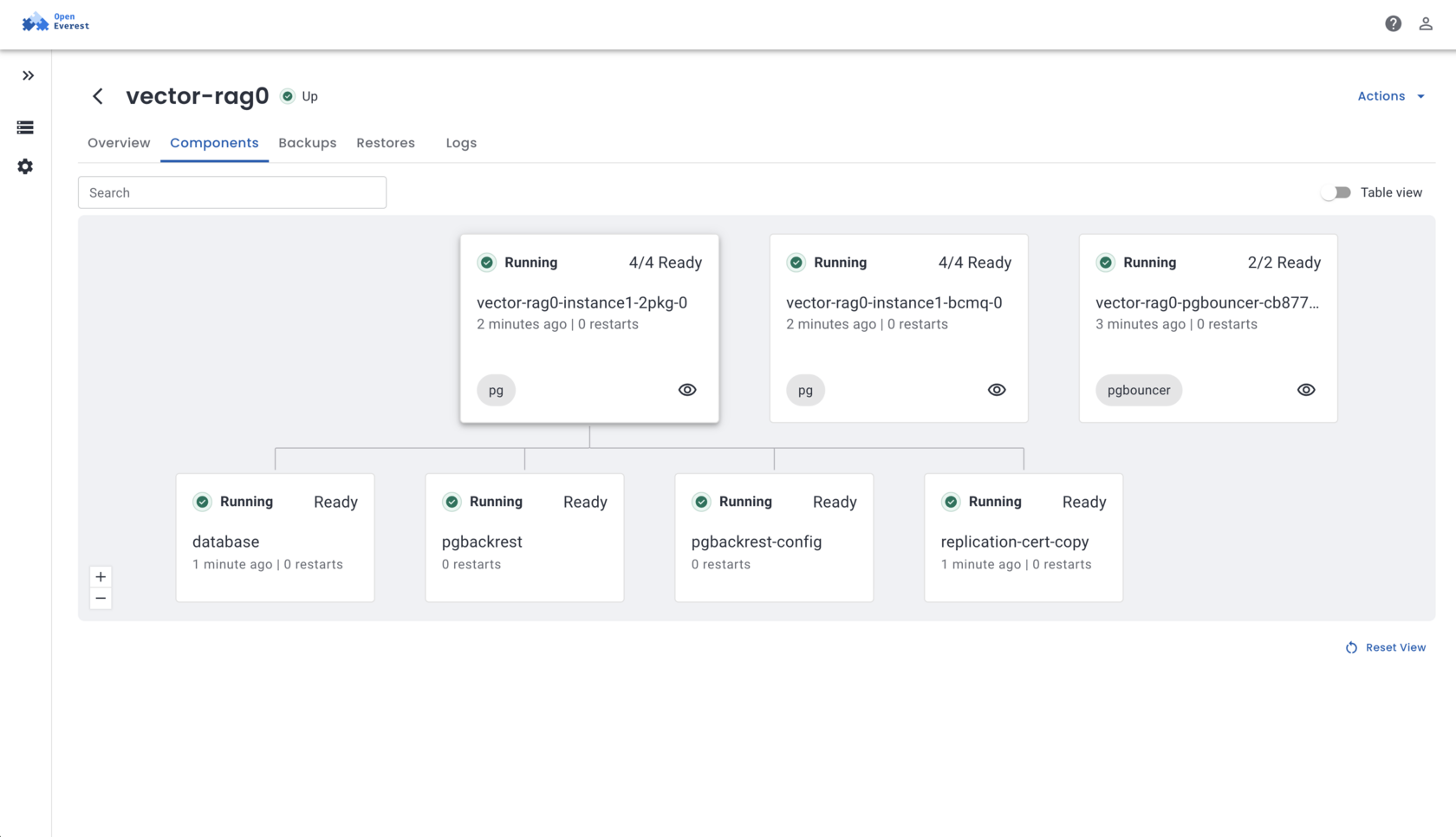
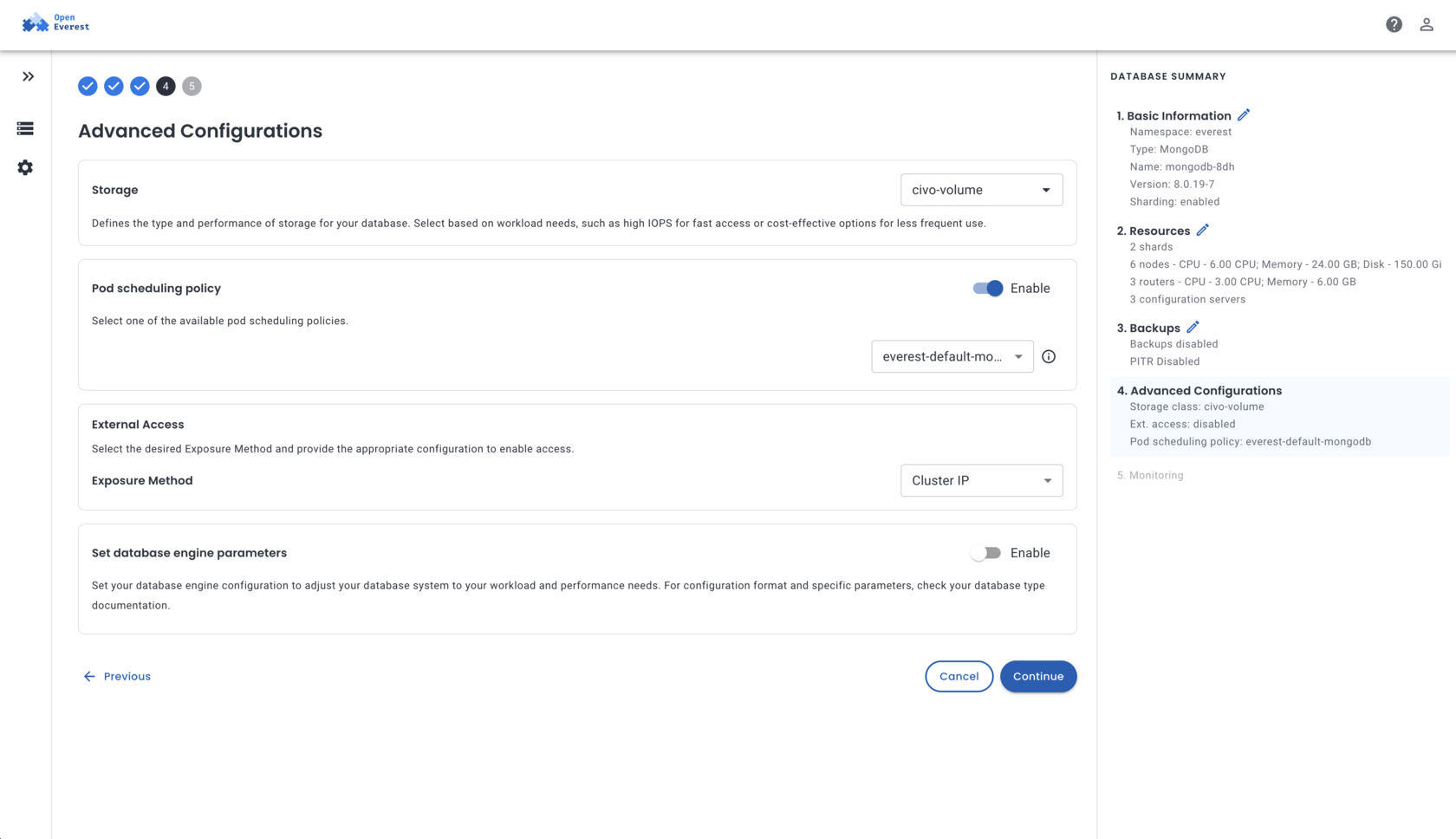
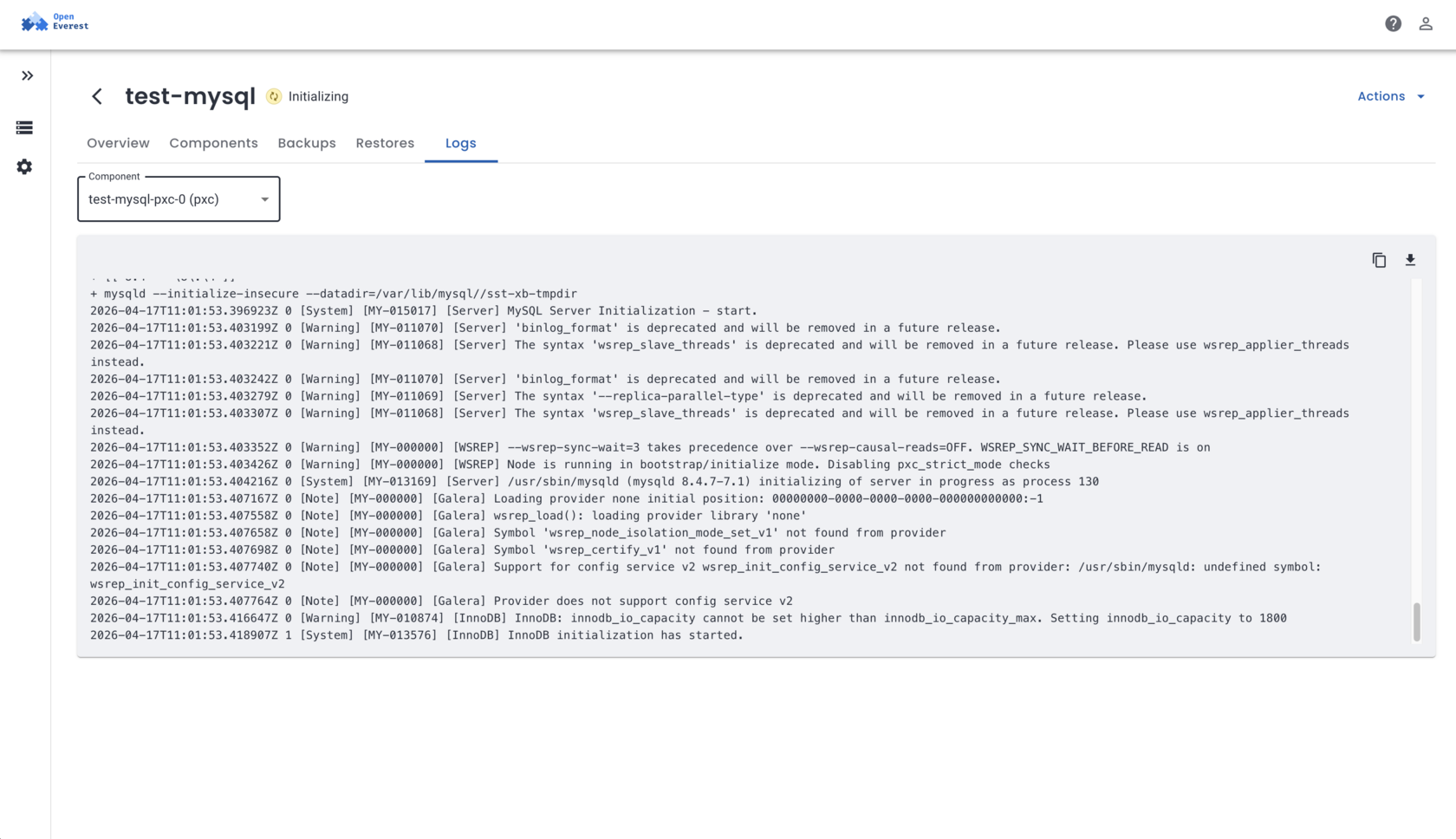
OpenEverest
The Road Ahead
Where we're taking the platform — and what we're building toward
Truly Open Source
Donated to the CNCF Sandbox — vendor-neutral governance, open roadmap, community-driven development. No proprietary lock-in. Ever.
Modular Architecture
Plugin any data engine, storage backend, or AI tool. Custom plugins execute operations, integrate tooling, discover & modify data. Built-in AI copilot for operations teams.
Run Truly Anywhere
Multi-cluster deployments, multi-geo data distribution, unified control plane across cloud, on-prem, and hybrid environments — from a single UI.
Thank you!
Questions?
Sergey Pronin · Founder, Solanica Inc. · Maintainer, OpenEverest · Cloud Native Gandhinagar, April 2026