
Age Gap Is Not a Problem
MySQL × Cloud-Native
Sergey Pronin Founder, Solanica Inc. · Maintainer, OpenEverest
The Age Gap
MySQL turned 19 when Kubernetes was born
18 years
🎬 Toy Story premieres
1995 MySQL 1.0 
📖 Wikipedia launches
2001
📱 First iPhone announced
2007
2013 Docker
2014 Kubernetes 
2018 Operator SDK
2019 Percona
Operator
for MySQL
Operator
for MySQL
Pre-databases 
Yes, I used to have hair.
Then I started running databases on Kubernetes.
Why listen to me
I've been on both sides of this problem.
- Before Ran lots of Kubernetes clusters. Convinced K8s was for stateless workloads only.
- 5 yrs @ Percona Led product teams. First assignment: build operators for databases.
- Today Founder, Solanica · maintainer, OpenEverest (CNCF).
One UI for all your databases.
 openeverest/openeverest
openeverest/openeverest 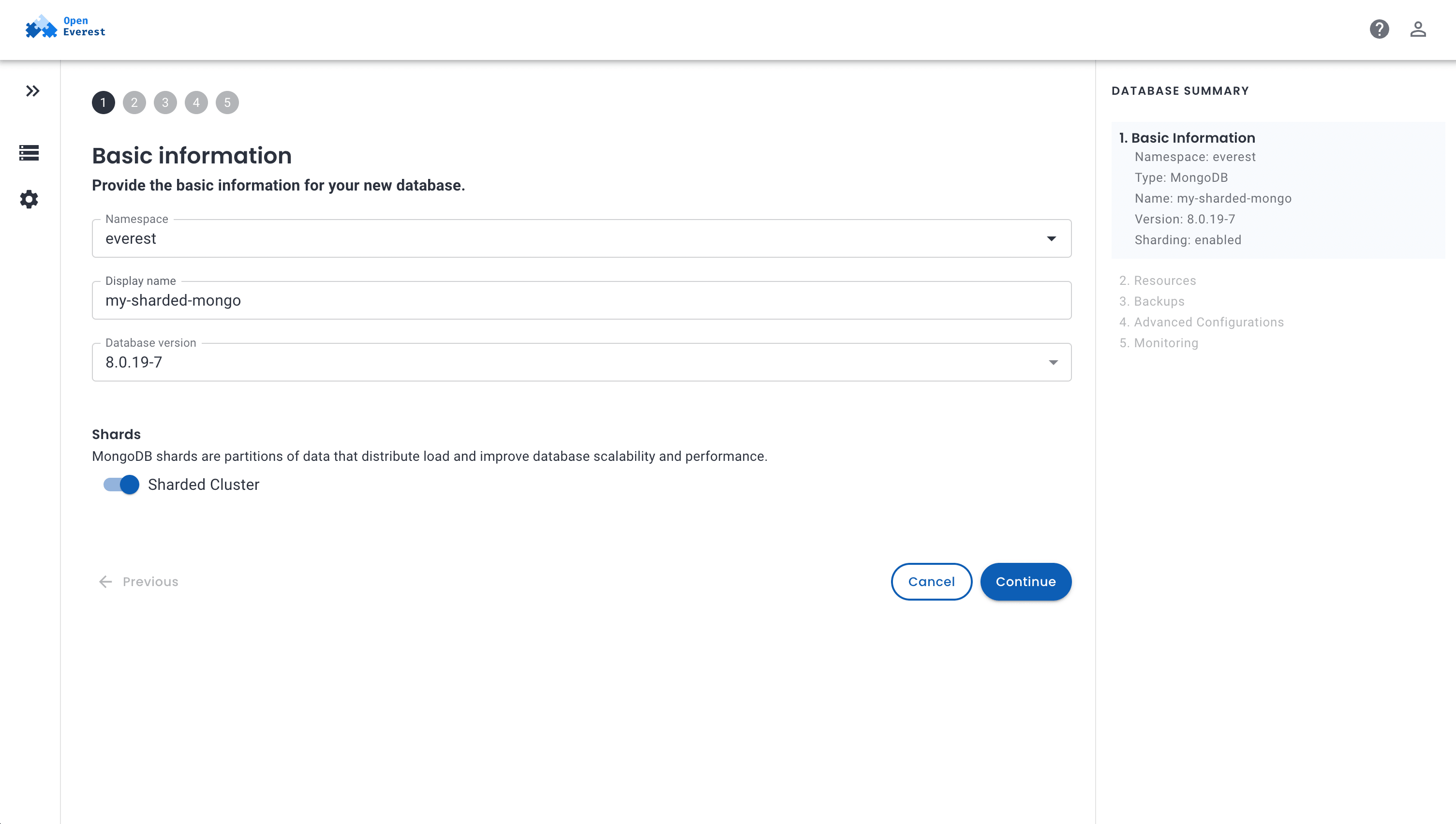 openeverest.io
openeverest.io Community
A vendor-neutral home for MySQL.
501(c)(6) nonprofit · independent of Oracle · launched May 2026
oursqlfoundation.org
Sign the open letter letter.3306-db.org